
Bytes, bits y cómo representarlos
When reproducing, using, or extracting this text, always reference the source and the author : Ignacio Rondini
Bytes, bits y cómo representarlos
Este artículo fue inicialmente publicado en el año 2021 en mi antiguo blog. Esta es una reedición.
¿Qué es un bit y un byte?
Aunque llevaba ya programando desde un buen momento, me tomó un tiempo darme cuenta de que al fin y al cabo, todo se reduce a una secuencia de bits. Cada archivo que tenemos en nuestros computadores o teléfonos, no son nada más ni nada menos que una serie de bits ordenados de cierta manera, siguiendo una estructura predefinida. Lo que diferencia una imagen de un archivo de texto, es cómo la secuencia de bits tienen diferentes estructuras para que puedan ser interpretados correctamente.
Comencemos por lo primero. Un byte es simplemente una secuencia de 8 bits. Un bit, a su vez, es cualquier sistema que pueda estar en dos estados diferentes. Habitualmente, dichos estados son representados por el número 1 y por el número 0. Por ejemplo, 1 podría significar que una corriente eléctrica pasa por cierto dispositivo, y 0, que no hay corriente. Pero en sí mismo, el soporte físico no es importante para nosotros.
Un byte es entonces una secuencia de 8 estados seguidos que podemos escribir como una serie de ocho 1 o 0. Por ejemplo, un byte puede escribirse como (0000 1000), lo que representa que el quinto bit de la secuencia está en el estado 1 y los otros en el estado 0. Esto significa que, en total, hay 2^8 = 256 estados diferentes.
También podemos representar un byte como un número en binario o en decimal. De esta forma, tenemos la siguiente representación (en representación decimal):
(0000 0000) = 0
(0000 0001) = 1
(0000 0010) = 2
(0000 0011) = 3
(1111 1111) = 255Personalmente, la representación que más me gusta es en forma de número hexadecimal de dos dígitos. O sea:
(0000 0000) = 0x00
(0000 0001) = 0x01
(0000 0010) = 0x02
(0000 0011) = 0x03
(0000 1010)= 0x0A
(1111 1111) = 0xFFDe este modo, una serie de N bytes puede representarse como un hexadecimal de 2N dígitos.
Para poder visualizar todo mejor, podemos usar la calculadora de Windows en modo programación (o cualquier otra aplicación que lo permita) y ver cómo diferentes números equivalen a diferentes bytes. Acá podemos ver que el byte: (1100 1001) es equivalente a 0xCA o 202.
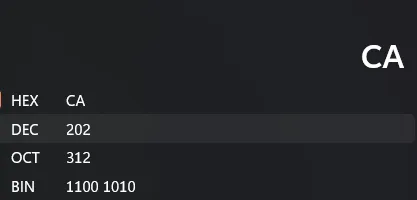
Esta representación funciona en los dos sentidos. Podemos interpretar un byte como un número, o podemos representar un número como un byte. Sin embargo, una serie de bytes también puede representar una serie de caracteres, por ejemplo usando ASCII o Unicode.
La verdad es que una serie de bytes puede corresponder con lo que uno quiera, ya que lo único que necesitamos es una función o mapa entre los diferentes valores de un byte y lo que queremos representar. Esa es la gran versatilidad, solo necesitamos una convención para interpretarlo.
Otra aplicación que suelo utilizar para visualizar archivos en binarios es HxD o Notepad+. Pueden instalarla y abrir cualquier archivo que quieran. Podrán así ver la representación en hexadecimal y la interpretación en texto de los bytes, en la parte derecha. En este caso, es la representación binaria de la imagen precedente.

Lo importante de recordar es que, hagamos lo que hagamos, esencialmente siempre estamos manipulando bytes. Y que un archivo es simplemente una estructura para interpretar esos bytes.
Ejemplo en java
Imaginemos que tenemos una estructura llamada TaggedString descrita por:
Tag (4 bytes)
Data (12 bytes)En la parte Data, vamos a almacenar un string de no más de 12 bytes en UTF-8.
El tag puede ser 0x10000001 o 0x00000001 e indica que si:
Tag==0x10000001 ==> el string debe ser interpretado en mayúscula
Tag==0x00000001 ==> el string debe ser interpretado en minúsculaComo premier ejercicio vamos a crear una clase en java que permita modelizar este tipo de estructura. Lo primero que debemos hacer es crear un Enum con los tags permitidos.
enum AllowedTag {
UPPERCASE(0x10000001),
LOWERCASE(0x00000001);
final int value;
AllowedTag(int value) {
this.value = value;
}
public static AllowedTag fromInt(int value) {
for (AllowedTag tag : AllowedTag.values()) {
if (tag.value == value) {
return tag;
}
}
throw new IllegalArgumentException("Illegal tag " + Integer.toHexString(value));
}Luego, vamos a utilizar un constructor que cree un TaggedString a partir de un byte array. Para ello vamos a copiar los primeros 4 bytes y transformarlos en un Tag y luego copiaremos los 12 siguientes bytes y crearemos el String que corresponda.
public TaggedString(byte[] rawTaggedString) throws UnsupportedEncodingException {
byte[] rawTag = new byte[TAG_SIZE];
byte[] rawData = new byte[DATA_SIZE];
System.arraycopy(rawTaggedString, 0, rawTag, 0, TAG_SIZE);
System.arraycopy(rawTaggedString, TAG_SIZE, rawData, 0, DATA_SIZE);
String rawValue = new String(rawData, StandardCharsets.UTF_8);
int tagAsInt = ByteBuffer.wrap(rawTag).getInt();
AllowedTag tag = AllowedTag.fromInt(tagAsInt);
switch (tag) {
case UPPERCASE:
this.value = rawValue.toUpperCase();
break;
case LOWERCASE:
this.value = rawValue.toLowerCase();
break;
default:
throw new IllegalArgumentException("Unsupported Tag" + tag);
}
}Luego lo único que nos queda es probar nuestra nueva clase. Para ello crearemos dos tests: uno para las minúsculas y otro para las mayúsculas. Hay que notar que en el test, debemos agregar espacios en blanco luego de nuestro string, lo que corresponde a los bytes no utilizados en nuestra estructura. En nuestro caso “Test” usa 4 bytes y nos quedan 8 bytes no utilizados, los cuales corresponden a un espacio.
public class TaggedStringTest {
@Test
public void TaggedString_uppercase() throws UnsupportedEncodingException {
ByteBuffer buffer = ByteBuffer.allocate(0x10);
buffer.putInt(TaggedString.AllowedTag.UPPERCASE.getValue());
buffer.put("TeSt".getBytes());
buffer.flip();
TaggedString taggedString = new TaggedString(buffer.array());
Assert.assertEquals("TEST\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000",taggedString.getValue());
}
@Test
public void TaggedString_lowercase() throws UnsupportedEncodingException {
ByteBuffer buffer = ByteBuffer.allocate(0x10);
buffer.putInt(TaggedString.AllowedTag.LOWERCASE.getValue());
buffer.put("TeSt".getBytes());
buffer.flip();
TaggedString taggedString = new TaggedString(buffer.array());
Assert.assertEquals("test\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000",taggedString.getValue());
}
}